pdf2docx开发概要:提取文本、图片和形状¶
发布于:2020-07-14 | 分类:process automation
文本、图片及形状涵盖了常见的PDF元素,这些是pdf2docx的处理对象。本文介绍利用PyMuPDF提取这些页面元素,及其基本数据结构。
文本与图片¶
PyMuPDF的Textpage对象提供的extractDICT()和extractRAWDICT()用以获取页面中的所有文本和图片(内容、位置、属性),基本数据结构如下 1:
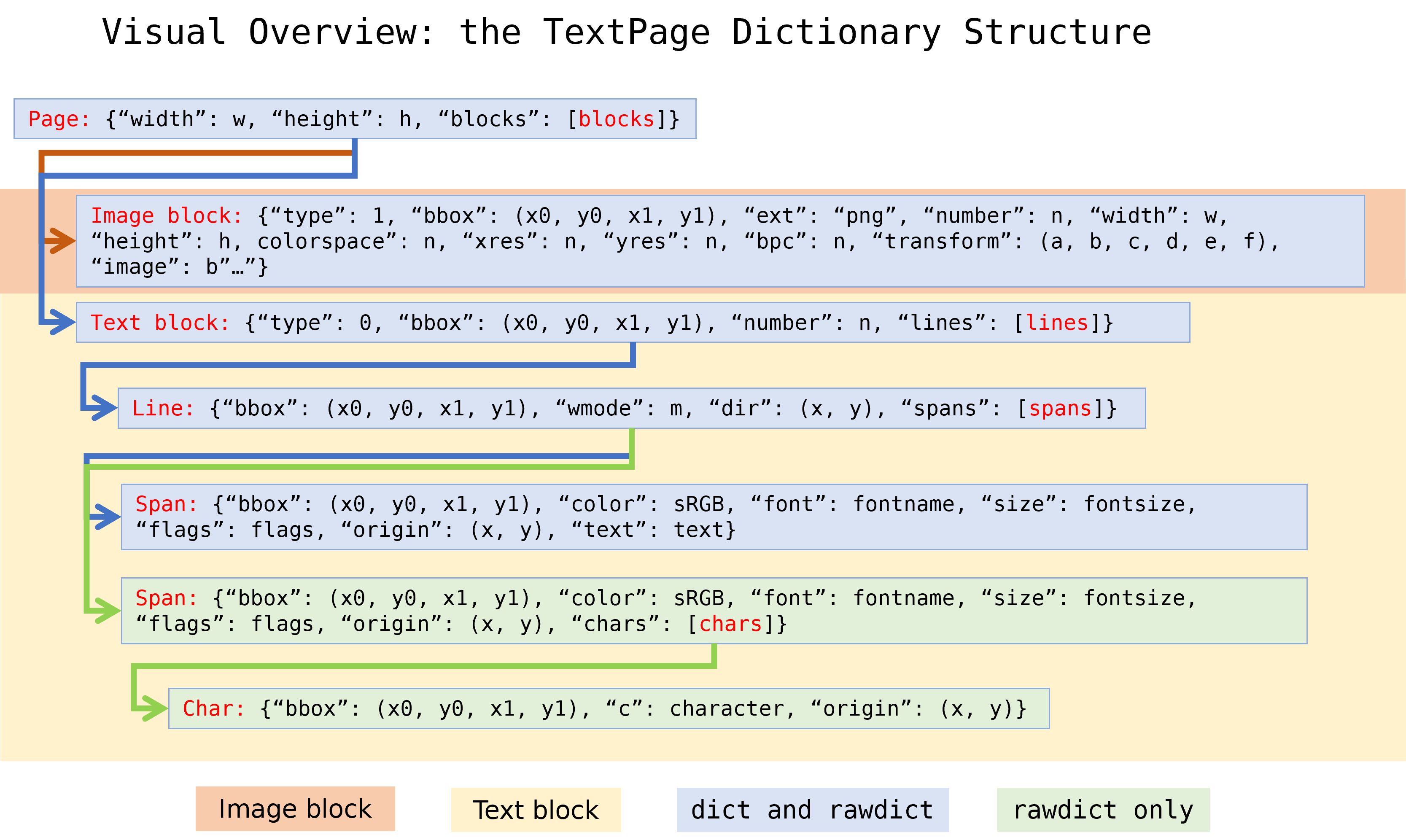
pdf2docx继续沿用以上数据结构,并稍作改动,作为第一类基本数据Block:
-
将图片块整合到文本块
TextBlock中,作为line>span级别的元素 -
增加布局参数,例如
alignment,left_space,before_space,用以保存后续段落布局解析结果
注意
后续版本中发现extractDICT()获取图片存在问题(如只能获取完全显示在页面中的图片、丢失alpha通道),还需配合page.getImageList()处理;另外,v0.5.0版本中对浮动图片也进行了支持,详见以下两篇图片相关的记录。
形状¶
文本与图片构成了主体内容,它们的样式则由 形状 来描述,例如代表文本高亮的矩形块,表明表格边线的直线(很细的矩形)。形状构成了pdf2docx的第二类基本数据Shape。
这里的所谓的形状具体指两类来源:
-
PDF原始文件中的路径
Path -
PDF注释
Annotation
(a) 路径¶
PDF规范定义了各种路径及其围成的图形(描边和填充),但截至1.17.3版本,PyMuPDF尚未提供解析具体路径的API,只能提取这些路径的原始代码(参考以下输出示例)。
pdf = fitz.open(file_path)
for page in pdf:
for xref in page._getContents():
page_content = pdf._getXrefStream(xref).decode(encoding="ISO-8859-1")
# 输出示例
/P<</MCID 0>> BDC
...
1 0 0 1 90.0240021 590.380005 cm
...
1 1 0 rg # or 0 g
...
285.17 500.11 193.97 13.44 re f*
...
214 320 m
249 322 l
...
EMC因此需要参考厚厚的PDF规范 2,自行从原始内容中解析。例如:
cm:坐标变换,本例(0,0)平移至(90.0240021 590.380005)q/Q:保存/调出画笔rg/g:指定颜色模式:RGB/灰度re,f/f*: 使用预定颜色填充矩形路径。如果没有f/f*,则仅仅是矩形路径而不进行填充。本例中,- 填充黄色 (1,1,0)
- 矩形左下角: (285.17 500.11)
- 宽度: 193.97 Pt
- 高度: 13.44 Pt
m,l: 从m向l画直线路径;后续可以继续l,表示多边形路径c,v,y: 根据控制点画贝塞尔曲线路径
关于坐标变换,也就是从PDF中提取的一个坐标映射到PyMuPDF处理的坐标,需要注意:
- PDF规范定义了一个原始的PDF坐标系(原点在左下角),cm定义了此坐标系下的变换矩阵
- PyMuPDF定义了fitz坐标系(原点左上角,页面旋转角度0),从PDF坐标系到fitz坐标系的变换矩阵page.transformationMatrix
- 真实页面可能存在旋转角度,所以fitz坐标系到真实页面坐标系的变换矩阵page.rotationMatrix
上述的PDF路径解析是一个复杂的工程,pdf2docx提供了简化版的解析函数,可以提取出常规的路径坐标、颜色、描边/填充状态。其中,我们只关注水平或者竖直的路径,因为只有它们对接下来的表格、文本样式解析有意义。
至于其他的曲线路径,实际上组成了矢量图形,pdf2docx将其转化为位图,便于插入到docx文档中,具体参考下文:
(b) 形状注释¶
在PDF文件基础上进行的批注操作例如高亮、下划线,可以直接使用Page对象的annots()方法获取,其中的type属性表明了该批注的类型 3。例如,pdf2docx关心的有:
PDF_ANNOT_LINE 3
PDF_ANNOT_SQUARE 4
PDF_ANNOT_HIGHLIGHT 8
PDF_ANNOT_UNDERLINE 9
PDF_ANNOT_STRIKEOUT 11
综合以上两类形状(路径和注释),将其分为两类:
- 描边(
Stroke)即较细的矩形,表征表格边框线、文字下划线、删除线等样式 - 填充(
Fill)即普通矩形,表征单元格背景色、文本高亮等样式
相应数据结构如下:
# Stroke
{
'type': int,
'start': (x0, y0),
'end': (x1, y1),
'width': w,
'bbox': (x0+w/2, y0+w/2, x1+w/2, y1+w/2),
'color': int # e.g. 16711680
}
# Fill
{
'type': int,
'bbox': (x0, y0, x1, y1),
'color': int # e.g. 16711680
}其中,type表示语义上的分类,即上述提及的表格样式(边框、背景色)、文本样式(高亮、下划线、删除线)。
注意
从1.18.0版本开始,PyMuPDF提供了获取页面内所有路径(包括Annotation)的函数page.getDrawings() 。虽然该方法尚不稳定(如丢失某些路径、不支持裁剪的路径),但可以使以上解析路径的过程大大简化,因此pdf2docx从v0.5.0开始使用该函数。
超链接¶
PyMuPDF可以通过page.getLinks()提取超链接,得到超链接文本、URI和作用区域(矩形坐标)。为了将超链接添加到相应的文本上去,pdf2docx将其作为一种虚拟的形状Hyperlink。
# hyperlink
{
'type': HYPERLINK,
'bbox': (x0, y0, x1, y1),
'uri': str
}
注意
Hyperlink类似于Stroke,本质区别在于Hyperlink的语义类型是已知的。更一般地理解,Stroke是一种几何类型,事先并不知道它的语义类型(边框、删除线还是下划线?);而Hyperlink是一种确定了语义类型的Stroke。
总结¶
借助PyMuPDF从PDF提取文本、图片和形状数据,它们构成了pdf2docx的两类基础数据:
-
块元素
Block,代表主体内容,例如直接提取出的文本/图片组成的TextBlock,以及后续解析得到的表格结构TableBlock。 -
形状元素
Shape,代表格式内容,例如描边Stroke将对应下划线、表格边框等,填充Fill将对应文本高亮、单元格背景色等。